GeneSys
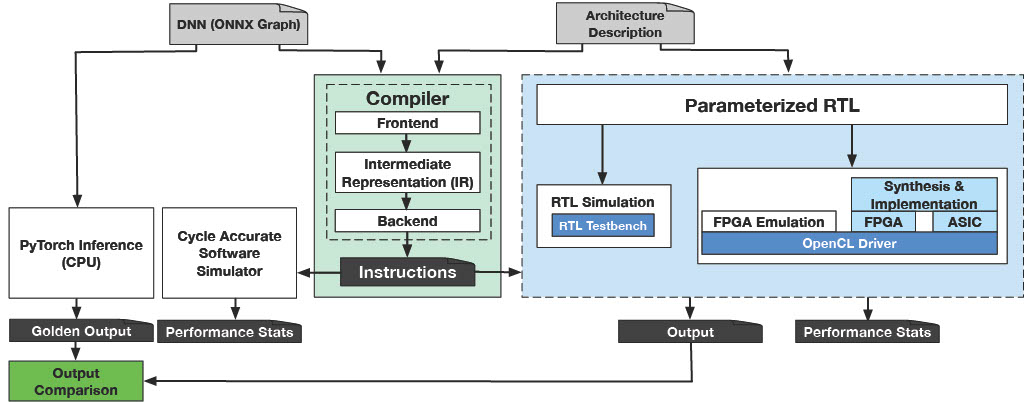
GeneSys workflow.
One of the major enabling factors in the significant advancement of deep learning (like convolutional and transformer-based neural networks) is the rapid growth of computing power in the 2010s. With the end of Dennard scaling (Dennard et al., 1974) and the advent of dark silicon (Esmaeilzadeh et al., 2011), research and development has shifted towards adopting hardware accelerators for deep learning (Chen et al., 2014; Sharma et al., 2016; Chen et al., 2016; Shao et al., 2019; Genc et al., 2021). Deep neural network (DNN) accelerators have found their way into production datacenters (Jouppi et al., 2017; Anderson et al., 2021; Jouppi et al., 2021), autonomous vehicles (Lin et al., 2018), internet of things (IoT) devices (Reagen et al., 2016; Whatmough et al., 2018), and biomedical devices (Kim et al., 2014; Liu et al., 2021). Besides the challenging task of designing hardware accelerators that abide by various power, performance, and area constraints, there is also ongoing research on how to seamlessly integrate hardware accelerators in the software stack (Ma et al., 2020; Yu et al., 2020; Korolija et al., 2020). Therefore, we must shift the focus from standalone hardware to holistic system design.
The Alternative Computing Technologies (ACT) Lab, led by my advisor Hadi Esmaeilzadeh, is one of the few in academia to have developed a fully fledged programmable accelerator generator, called GeneSys. GeneSys is a full-stack system designed to accelerate deep learning models such as convolutional neural networks (CNNs) and transformers-based language models. It comprises a parameterizable neural processing unit (NPU) generator capable of creating hardware accelerators with various configurations, which has been both taped out and prototyped on AWS F1 FPGAs. GeneSys also features a multi-target compilation stack that supports algorithms beyond deep learning, OpenCL-based Linux drivers, user-friendly Python APIs, and an RTL verification framework with a regression suite including synthetic and state-of-the-art DNN benchmarks like ResNet50, BERT, and GPT2. Additionally, it includes hardware synthesis scripts, a software simulator for profiling, and comprehensive software support. These unique and functional artifacts represent years of research and multiple published papers by the ACT Lab (Mahajan et al., 2016; Sharma et al., 2016; Sharma et al., 2018; Ghodrati et al., 2020; Kinzer et al., 2021; Kim et al., 2022). GeneSys has already been used in multiple published papers (Wang et al., 2024; Ghodrati et al., 2024; Mahapatra et al., 2024) and course projects in CSE 240D at the University of California San Diego.
My primary contribution to GeneSys has been the continued development of the system’s compiler, which was originally written by Sean Kinzer. After taking on the mantle, I streamlined the setup and installation process by packaging the compiler with pip, implemented a new greedy memory allocation strategy based on (Pisarchyk & Lee, 2020) which significantly reduced the memory footprint in DRAM during execution, removed excess code bloat leftover from stitching multiple projects together during the initial development phase, and expanded the neural network layer support of the compiler to accommodate more diverse models. I also had the opportunity to give oral presentations on the compiler through tutorials organized by ACT Lab. The tutorials were presented at the following venues:
- IEEE/ACM International Symposium on Microarchitecture (MICRO) on October 29th, 2023 in Toronto, Canada
- IEEE International Symposium on High-Performance Computer Architecture (HPCA) on March 2nd, 2024 in Edinburgh, Scotland
- ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS) on April 28th, 2024 in San Diego, California
- International Symposium on Computer Architecture (ISCA) on June 29th, 2024 in Buenos Aires, Argentina.
For more information on the project as a whole, see the GeneSys website.
References
2024
- Wang, S.-T., Xu, H., Mamandipoor, A., Mahapatra, R., Ahn, B. H., Ghodrati, S., Kailas, K., Alian, M., & Esmaeilzadeh, H. (2024). Data Motion Acceleration: Chaining Cross-Domain Multi Accelerators. 2024 IEEE International Symposium on High-Performance Computer Architecture (HPCA), 1043–1062. https://doi.org/10.1109/HPCA57654.2024.00083
- Ghodrati, S., Kinzer, S., Xu, H., Mahapatra, R., Kim, Y., Ahn, B. H., Wang, D. K., Karthikeyan, L., Yazdanbakhsh, A., Park, J., Kim, N. S., & Esmaeilzadeh, H. (2024). Tandem Processor: Grappling with Emerging Operators in Neural Networks. Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, 1165–1182. https://doi.org/10.1145/3620665.3640365
- Mahapatra, R., Ghodrati, S., Ahn, B. H., Kinzer, S., Wang, S.-T., Xu, H., Karthikeyan, L., Sharma, H., Yazdanbakhsh, A., Alian, M., & Esmaeilzadeh, H. (2024). In-Storage Domain-Specific Acceleration for Serverless Computing. Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, 530–548. https://doi.org/10.1145/3620665.3640413
2022
- Kim, J. K., Ahn, B. H., Kinzer, S., Ghodrati, S., Mahapatra, R., Yatham, B., Wang, S.-T., Kim, D., Sarikhani, P., Mahmoudi, B., Mahajan, D., Park, J., & Esmaeilzadeh, H. (2022). Yin-Yang: Programming Abstractions for Cross-Domain Multi-Acceleration. IEEE Micro, 42(5), 89–98. https://doi.org/10.1109/MM.2022.3189416
2021
- Genc, H., Kim, S., Amid, A., Haj-Ali, A., Iyer, V., Prakash, P., Zhao, J., Grubb, D., Liew, H., Mao, H., Ou, A., Schmidt, C., Steffl, S., Wright, J., Stoica, I., Ragan-Kelley, J., Asanovic, K., Nikolic, B., & Shao, Y. S. (2021). Gemmini: Enabling Systematic Deep-Learning Architecture Evaluation via Full-Stack Integration. 2021 58th ACM/IEEE Design Automation Conference (DAC), 769–774. https://doi.org/10.1109/DAC18074.2021.9586216
- Anderson, M., Chen, B., Chen, S., Deng, S., Fix, J., Gschwind, M., Kalaiah, A., Kim, C., Lee, J., Liang, J., Liu, H., Lu, Y., Montgomery, J., Moorthy, A., Nadathur, S., Naghshineh, S., Nayak, A., Park, J., Petersen, C., … Rao, V. (2021). First-Generation Inference Accelerator Deployment at Facebook. https://arxiv.org/abs/2107.04140
- Jouppi, N. P., Yoon, D. H., Ashcraft, M., Gottscho, M., Jablin, T. B., Kurian, G., Laudon, J., Li, S., Ma, P., Ma, X., Norrie, T., Patil, N., Prasad, S., Young, C., Zhou, Z., & Patterson, D. (2021). Ten Lessons from Three Generations Shaped Google’s TPUv4i. Proceedings of the 48th Annual International Symposium on Computer Architecture, 1–14. https://doi.org/10.1109/ISCA52012.2021.00010
- Liu, J., Zhu, Z., Zhou, Y., Wang, N., Dai, G., Liu, Q., Xiao, J., Xie, Y., Zhong, Z., Liu, H., Chang, L., & Zhou, J. (2021). 4.5 BioAIP: A Reconfigurable Biomedical AI Processor with Adaptive Learning for Versatile Intelligent Health Monitoring. 2021 IEEE International Solid-State Circuits Conference (ISSCC), 62–64. https://doi.org/10.1109/ISSCC42613.2021.9365996
- Kinzer, S., Kim, J. K., Ghodrati, S., Yatham, B., Althoff, A., Mahajan, D., Lerner, S., & Esmaeilzadeh, H. (2021). A Computational Stack for Cross-Domain Acceleration. 2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA), 54–70. https://doi.org/10.1109/HPCA51647.2021.00015
2020
- Ma, J., Zuo, G., Loughlin, K., Cheng, X., Liu, Y., Eneyew, A. M., Qi, Z., & Kasikci, B. (2020). A Hypervisor for Shared-Memory FPGA Platforms. Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems, 827–844. https://doi.org/10.1145/3373376.3378482
- Yu, H., Peters, A. M., Akshintala, A., & Rossbach, C. J. (2020). AvA: Accelerated Virtualization of Accelerators. Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems, 807–825. https://doi.org/10.1145/3373376.3378466
- Korolija, D., Roscoe, T., & Alonso, G. (2020). Do OS Abstractions Make Sense on FPGAs? Proceedings of the 14th USENIX Conference on Operating Systems Design and Implementation, 991–1010. https://www.usenix.org/conference/osdi20/presentation/roscoe
- Ghodrati, S., Ahn, B. H., Kyung Kim, J., Kinzer, S., Yatham, B. R., Alla, N., Sharma, H., Alian, M., Ebrahimi, E., Kim, N. S., Young, C., & Esmaeilzadeh, H. (2020). Planaria: Dynamic Architecture Fission for Spatial Multi-Tenant Acceleration of Deep Neural Networks. 2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), 681–697. https://doi.org/10.1109/MICRO50266.2020.00062
- Pisarchyk, Y., & Lee, J. (2020). Efficient Memory Management for Deep Neural Net Inference. https://arxiv.org/abs/2001.03288
2019
- Shao, Y. S., Clemons, J., Venkatesan, R., Zimmer, B., Fojtik, M., Jiang, N., Keller, B., Klinefelter, A., Pinckney, N., Raina, P., Tell, S. G., Zhang, Y., Dally, W. J., Emer, J., Gray, C. T., Khailany, B., & Keckler, S. W. (2019). Simba: Scaling Deep-Learning Inference with Multi-Chip-Module-Based Architecture. Proceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, 14–27. https://doi.org/10.1145/3352460.3358302
2018
- Lin, S.-C., Zhang, Y., Hsu, C.-H., Skach, M., Haque, M. E., Tang, L., & Mars, J. (2018). The Architectural Implications of Autonomous Driving: Constraints and Acceleration. Proceedings of the Twenty-Third International Conference on Architectural Support for Programming Languages and Operating Systems, 751–766. https://doi.org/10.1145/3173162.3173191
- Whatmough, P. N., Lee, S. K., Brooks, D., & Wei, G.-Y. (2018). DNN Engine: A 28-nm Timing-Error Tolerant Sparse Deep Neural Network Processor for IoT Applications. IEEE Journal of Solid-State Circuits, 53(9), 2722–2731. https://doi.org/10.1109/JSSC.2018.2841824
- Sharma, H., Park, J., Suda, N., Lai, L., Chau, B., Kim, J. K., Chandra, V., & Esmaeilzadeh, H. (2018). Bit Fusion: Bit-Level Dynamically Composable Architecture for Accelerating Deep Neural Networks. Proceedings of the 45th Annual International Symposium on Computer Architecture, 764–775. https://doi.org/10.1109/ISCA.2018.00069
2017
- Jouppi, N. P., Young, C., Patil, N., Patterson, D., Agrawal, G., Bajwa, R., Bates, S., Bhatia, S., Boden, N., Borchers, A., Boyle, R., Cantin, P.-luc, Chao, C., Clark, C., Coriell, J., Daley, M., Dau, M., Dean, J., Gelb, B., … Yoon, D. H. (2017). In-Datacenter Performance Analysis of a Tensor Processing Unit. 2017 ACM/IEEE 44th Annual International Symposium on Computer Architecture (ISCA), 1–12. https://doi.org/10.1145/3079856.3080246
2016
- Sharma, H., Park, J., Mahajan, D., Amaro, E., Kim, J. K., Shao, C., Mishra, A., & Esmaeilzadeh, H. (2016). From High-Level Deep Neural Models to FPGAs. 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), 1–12. https://doi.org/10.1109/MICRO.2016.7783720
- Chen, Y.-H., Emer, J., & Sze, V. (2016). Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks. Proceedings of the 43rd International Symposium on Computer Architecture, 367–379. https://doi.org/10.1109/ISCA.2016.40
- Reagen, B., Whatmough, P., Adolf, R., Rama, S., Lee, H., Lee, S. K., Hernández-Lobato, J. M., Wei, G.-Y., & Brooks, D. (2016). Minerva: Enabling Low-Power, Highly-Accurate Deep Neural Network Accelerators. 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), 267–278. https://doi.org/10.1109/ISCA.2016.32
- Mahajan, D., Park, J., Amaro, E., Sharma, H., Yazdanbakhsh, A., Kim, J. K., & Esmaeilzadeh, H. (2016). TABLA: A Unified Template-Based Framework for Accelerating Statistical Machine Learning. 2016 IEEE International Symposium on High Performance Computer Architecture (HPCA), 14–26. https://doi.org/10.1109/HPCA.2016.7446050
2014
- Chen, T., Du, Z., Sun, N., Wang, J., Wu, C., Chen, Y., & Temam, O. (2014). DianNao: A Small-Footprint High-Throughput Accelerator for Ubiquitous Machine-Learning. Proceedings of the 19th International Conference on Architectural Support for Programming Languages and Operating Systems, 269–284. https://doi.org/10.1145/2541940.2541967
- Kim, C., Chung, M., Cho, Y., Konijnenburg, M., Ryu, S., & Kim, J. (2014). ULP-SRP: Ultra Low-Power Samsung Reconfigurable Processor for Biomedical Applications. ACM Trans. Reconfigurable Technol. Syst., 7(3). https://doi.org/10.1145/2629610
2011
- Esmaeilzadeh, H., Blem, E., St. Amant, R., Sankaralingam, K., & Burger, D. (2011). Dark Silicon and the End of Multicore Scaling. Proceedings of the 38th Annual International Symposium on Computer Architecture, 365–376. https://doi.org/10.1145/2000064.2000108
1974
- Dennard, R. H., Gaensslen, F. H., Yu, H.-N., Rideout, V. L., Bassous, E., & LeBlanc, A. R. (1974). Design of Ion-Implanted MOSFET’s with Very Small Physical Dimensions. IEEE Journal of Solid-State Circuits, 9(5), 256–268. https://doi.org/10.1109/JSSC.1974.1050511